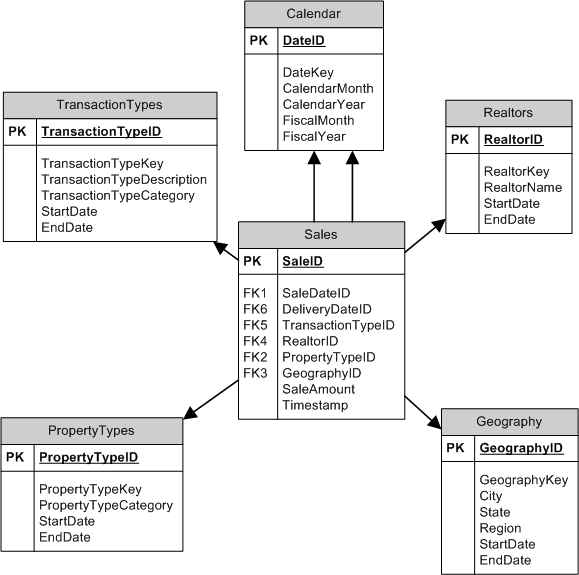
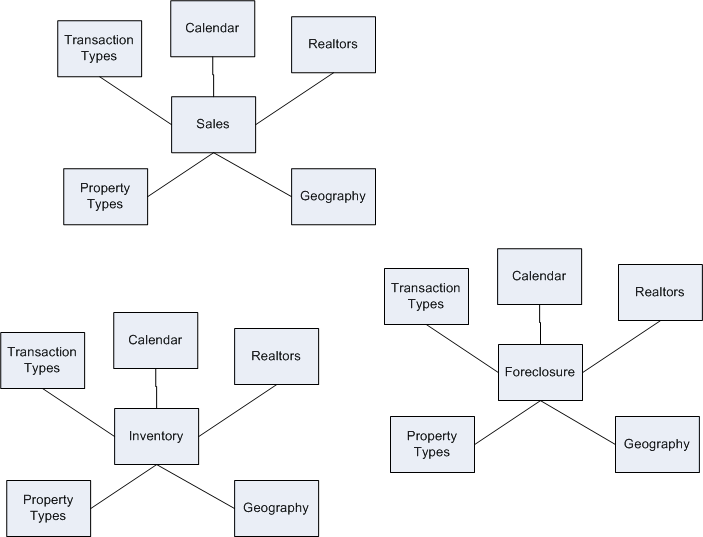
Spelunking, for those who don’t know is exploring caves. In some ways, that’s what it’s like to find your way around in databases in some organizations. It’s especially difficult without a flashlight.
This PowerPoint presentation will provide some tips, techniques, and several scripts that can help shed light on your data cavern.
The attached ZIP file has all of the scripts mentioned in the presentation.DatabaseSpelunking DatabaseSpelunkingScripts